Accelerated Data Science
Accelerated Machine Learning
Speedup your applications from your browser
using the power of accelerators
Launch an FPGA-enabled workspace in 1-click
Try now for free
Youtube
Linkedin
Github
Twitter
Medium
Trusted by

InAccel Studio: Speed up your applications from your browser
InAccel’s Accelerated Machine Learning Studio (AML) is a fully integrated framework that allows to speedup your C/C++, Python, Java and Scala applications with zero code changes.
It aims to maintain the practical and easy to use interface of other open-source frameworks and at the same time to accelerate the training or the classification part of machine learning models.
The accelerators can achieve up to 15x speedup compared to multi-threaded high performance processors. InAccel provides all the required APIs in Python, C/C++ and Java for the seamless integration of the accelerators with your applications.
InAccel studio is a managed cloud platform for data scientists and software developers. We provide the tools to utilize the power of FPGA accelerators in the most efficient way.
1-click (no-code) Demos
Inference (DL)
ResNet50 inference acceleration on multiple images using a cluster of FPGAs
Genomics
Smith-Waterman acceleration through an easy to use GUI on a cluster of FPGAs.
Compression
GZip compression acceleration through an easy to use GUI on a cluster of FPGAs.
Instant Acceleration
Check this 1-min video to learn how InAccel can help you speedup your ML and DL applications with zero code changes.
Enjoy 10x-20x speedup on your applications utilizing the power of accelerators stress-free.
Using familiar frameworks like Jupyter, Scikit Learn and Keras, Inaccel instantly offloads the most computationally intensive functions to the hardware accelerators.
Pay-as-you-go: Pay only for the days that you are using the InAccel studio in a secure cloud-based environment (using aws f1 instances).
Accelerated ML models
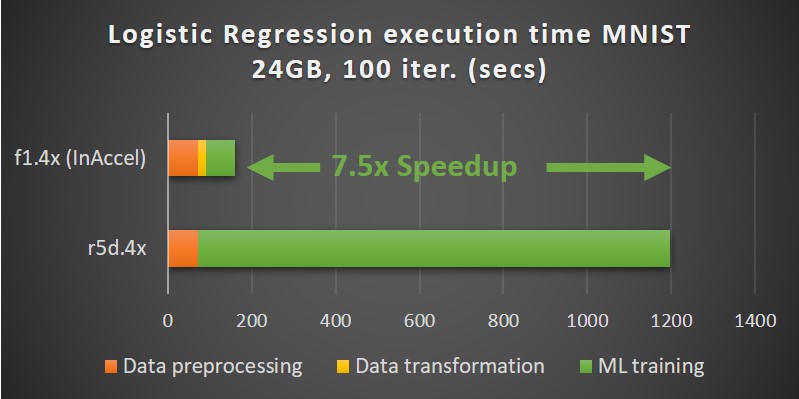
InAccel’s Accelerated ML suite can be used to significantly speedup widely-used machine learning applications like logistic regression and K-means clustering.
It also allows the available resources to be shared across multiple users as well as scalable deployments to multiple FPGA cards.
Available Accelerators:
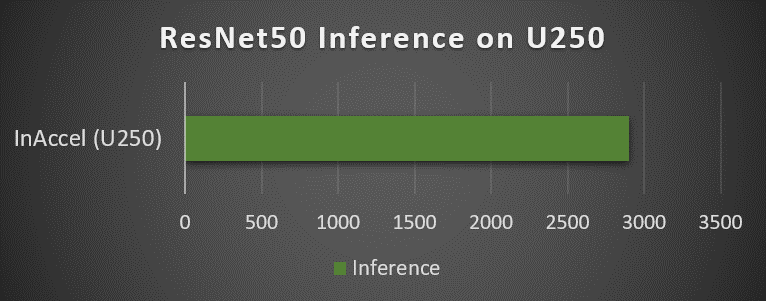
- Deep Neural networks – Inference (Resnet50)
- Logistic regression
- K-means clustering
- Naive Bayes
- XGboost
Save costs from faster execution
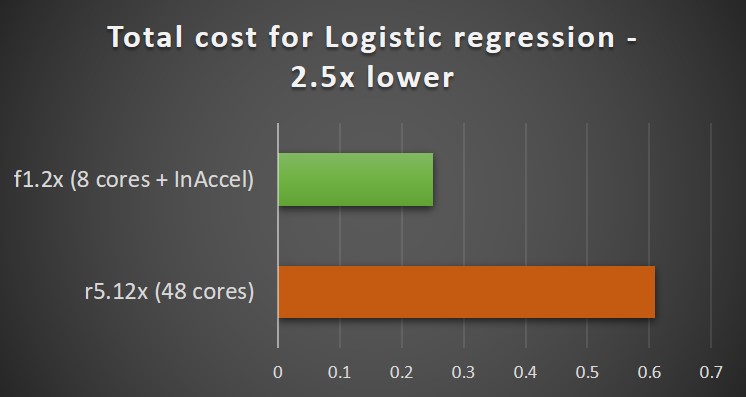
The speedup you achieve using InAccel’s ML suite comes also with a significant reduction on the operational expenses. While the accelerators cost higher (per hour) compared to typical processors, when you take into account the reduction of the total execution time, you can achieve up to 2.6 reduction on the operational expenses (TCO)
Faster execution time from Jupyter Notebooks
Speedup your ML applications instantly on Jupyter notebooks using InAccel’s Accelerated ML suite.
Check the video on how you can speedup your ML applications just with a click of a button on Jupyter notebooks.
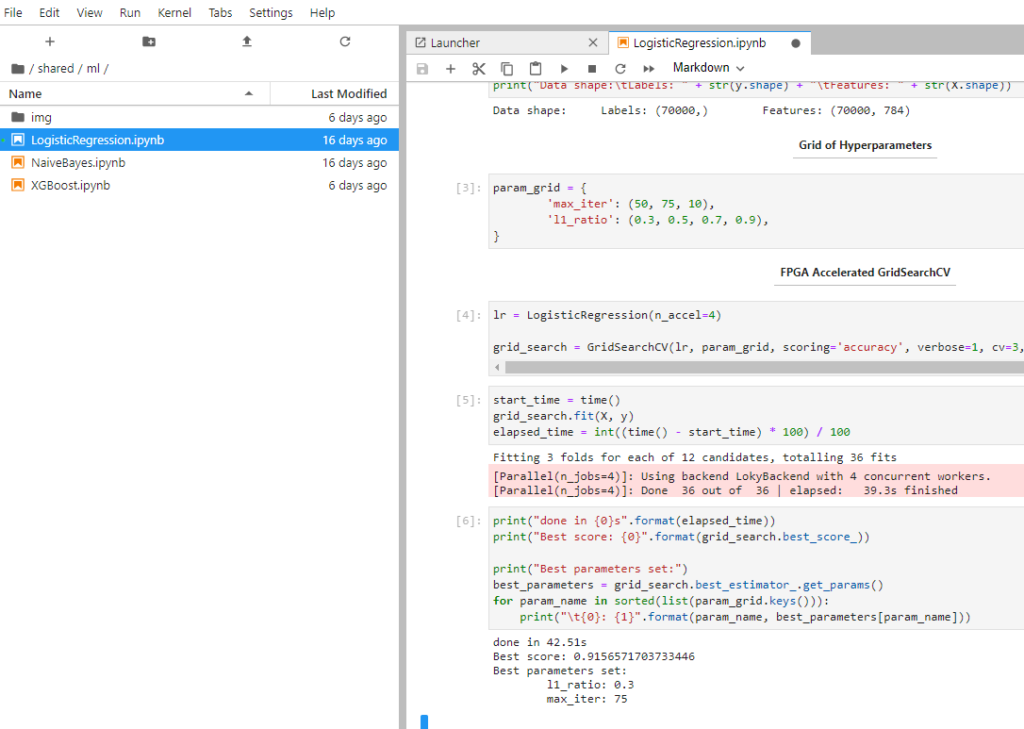
Same tools. Faster execution
Same notebook structure.
Just import the inaccel library and enjoy up to 15x faster execution time for your applications.
Speedup the hyper-parameter tuning, the training or even the classification with widely-used state-of-the-art tools.
Inference also supported (i.e. ResNet50) with high frame rates of up to 3,000 fps per FPGA card.
1. Log in
Log in securely using your Google account.
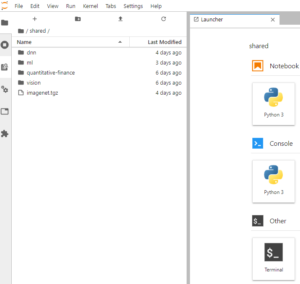
2. Select the application
Select the application that you need to speedup with ready to use examples
- Machine Learning (InAccel)
- DNN – Inference (ResNet50)
- Quantitative Finance (Vitis)
- Compression (Vitis)
- Encryption (Vitis)
- Vision (Vitis)
- Genomics
3. Run on your browser
Run your application from:
- Terminal
- Python
- Jupyter
Get instant acceleration just by invoking the function.

Note: The online web platform is available for demonstration purposes to promote the ease of deployment using FPGA-based accelerators. Multiple users may share the available resources which could affect the performance of the applications.
InAccel studio resources are not guaranteed and not unlimited, and the usage limits sometimes fluctuate. This is necessary for InAccel studio to be able to provide resources for free.
If you want to have exclusive access to speedup your applications contact us at info@inaccel.com.
Use cases
Machine Learning

Quantitative Finance
Deep Learning

Genomics

Partnerships
