Currently, cloud providers offer a plethora of choices when it comes to the processing platform that will be used to train your machine learning application. AWS, Alibaba cloud, Azure and Huawei offers several platforms such as general purpose CPUs, compute-optimized CPUs, memory-optimized CPUs, GPUs, FPGAs and Tensor Flow Processing Units.
Choosing one of these platforms in order to achieve the best performance, lower cost or better performance/cost is a challenging task and needs careful consideration and detailed planning. However there are some hints that can help you decide easier on which platform is best for your applications. This article gives a fast cheat-sheet on how to choose the best platform for your applications.
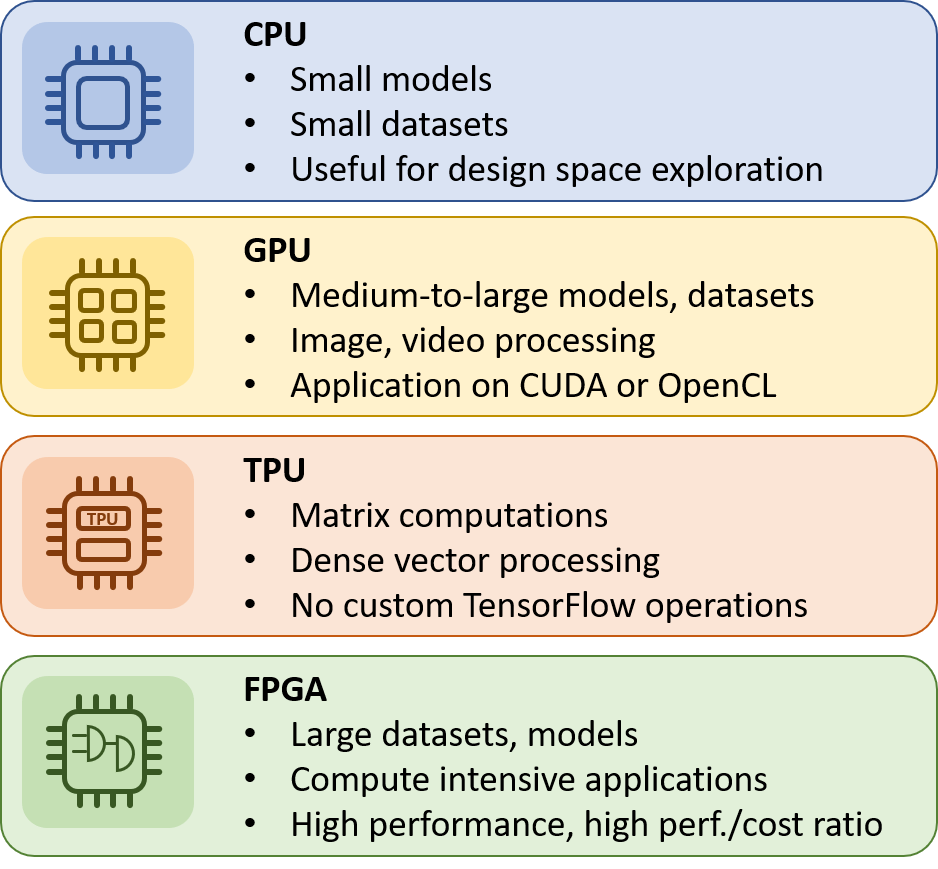
When to use CPUs:
The main advantage of CPUs is that it is very easy to program them and supports any programming framework. You can program them in C/C++, Scala, Java, Python or any other new language. That way it is very easy to do a fast design space exploration and run your applications. However, when it comes to machine learning training it is most suited for simple models that do not take long to train and for small models with small effective batch sizes. If you want to run large models and large datasets then the total execution time for machine learning training will be prohibited.
When to use GPUs:
GPUs are specialized processing units that were mainly designed to process images and videos. There are based on simpler processing units compared to CPUs but they can host much larger number of cores making them ideal for applications in which data need to be processed in parallel like the pixels of images or videos. However, GPUs are programmed in languages like CUDA and OpenCL and therefore provide limited flexibility compared to CPUs.
When to use TPU:
Tensorflow Processing Units have been designed from the bottom up to allow faster execution of application. TPUs are very fast at performing dense vector and matrix computations and are specialized on running very fast program based on Tensorflow. They are very well suited for applications dominated by matrix computations and for applications and models with no custom TensorFlow operations inside the main training loop. That means that they have lower flexibility compared to CPUs and GPUs and they only makes sense to use them when it comes to models based on the TensorFlow.
When to use FPGAs:
In the past FPGAs used to be a configurable chip that was mainly used to implement glue logic and custom functions. However, currently FPGAs have been emerged as a very powerful processing units that can be configured to meet applications requirements. In fact, using FPGAs we can make tailored-made architectures specialized for specific applications. That way we can achieve much higher performance, lower cost and lower power consumption compared to other options like CPUs and GPUs. FPGAs can be programmed now using OpenCL and High-level Synthesis (HLS) and that’s make it much easier to program than in the past. However, due to the this limitation FPGAs offer limited flexibility compared to other platforms.
The best way to use FPGAs to train a model is through the use of pre-configured architectures specialized for the applications that you are interested. That way you can achieve much higher performance than CPUs and GPUs and at the same time you do not have to change your code at a all. The pre-configured accelerated architectures provides all the required APIs and libraries for your programming framework (Python, Scala, Java, R and Apache Spark) that allows to overload the most computational intensive tasks and offload them in the FPGAs. That way, you get the best performance and you don’t have to write your applications to a specific platform/framework like TensorFlow. This is the approach that we have followed at InAccel. We have developed an integrated suite that includes both the optimized FPGA architecture for ML training and the software stack that allows the seamless integration of hardware accelerators without the need to change your code at all. And we have managed to integrated into a Docker container that makes it much easier to deploy and use.
The integrated platform allows data scientist to train up to 3x faster their machine learning models based on logistic regression, k-means clustering or recommendation engines over popular programming frameworks like Scala, Python and Spark ML. Now that FPGAs are available on the cloud, it is easier than ever to speedup your ML applications without the need to buy your own FPGA. You can check the performance of your ML training on the cloud using the InAccel Accelerated ML suite on AWS and check how to train 3x faster you model.
Speedup comparison: Pitfalls and fallacies
When it comes to selecting which hardware platform to choose to run your application you must pay extra attention to the benchmarks results and the comparison with other platforms. The comparison between platforms should always takes place using the same dataset, under the framework (i.e. Mahout, Spark, etc.) and should be always using the optimized version of the CPUs. That means that the reference design should always be the optimized version of the CPU using the optimized libraries for the specific applications (e.g. for machine learning many frameworks use the optimized BLAS library to perform the machine learning training). If the speedup comparison is made using as a reference the naive Scala or Python implementation this will lead to misleading conclusions. For example, just be writing an optimized version of the specific algorithm on C/C++ will offer significant advantage even for the same or lower performance platform. Therefore, the comparison should always be done using the most optimized version of the CPUs frameworks to make useful conclusions.
5 comments
Marisa April 13, 2019
Thanks, it's very informative
Here April 25, 2019
This is truly useful, thanks.
Simon May 12, 2019
Thanks for sharing this post, is very helpful article.
Zahra April 28, 2020
Thanks, great post
Ziv February 5, 2021
Thanks!