Training a ML model can take a lot of time especially when you have to process huge amounts of data. Typical general-purpose processors (CPUs) or GPUs are designed to be flexible but are not very efficient on machine learning training. In the domain on embedded systems, that problem was solved many years ago by using specialized chips that are designed for specific applications (i.e. FPGAs). FPGAs are programmable chips that can be configured with specialized architectures. In the FPGAs, instructions that needs to process the data are hard-wired in the chip. Therefore, they can achieve much better performance than CPUs and consume much lower power.
New paradigm shift — Accelerators on the cloud
The good news is that now cloud providers like AWS, Alibaba and Nimbix have started deploying FPGAs in the cloud that allows everyone to design its own specialized architecture. The bad news is that FPGAs are hard to program using specialized hardware description languages like VHDL, Verilog, HLS or OpenCL. Most Data Scientists and Data Engineers do not have the time to learn how to program FPGAs or GPUs. They just want to run faster their applications. Therefore the most efficient way to utilize FPGAs is through ready-to-use libraries. Cloud providers like AWS and Nimbix have repositories (a.k.a. marketplaces) that can be used to store the FPGA images for different kind of applications.
At InAccel we have developed a Machine Learning suite for the FPGAs provided recently by aws that can be used without changing a single line of your code. The provided libraries overload the specific functions for the machine learning (e.g. logistic regression, k-means clustering, etc.) and the processor just offload the specific functions to the FPGA. FPGA can execute up to 12x faster the ML task and then return the data to the processor.
InAccel Accelerated ML suite supports C/C++, Java, Python and Scala and is also fully compatible with Apache Spark. That means that you can run your Spark ML applications on aws without changing your code and you get a 3x overall improvement instantly. The best thing is that at the same time you can also reduce the TCO. As the spark application will run 3x faster and the overall cost is the same as a typical r5.12x instance, you cat get up to 3x savings on your monthly bills.
Spark ML acceleration using InAccel FPGAs
Dockers for seamless integration
The new version of InAccel’s ML suite is based on dockers. That means that all the APIs, libraries and configuration files are all integrated in a simple to use package that allows direct integration with your applications. The most important feature of InAccel ML suite is that the user does not have to change the code at all.
The data scientist/engineer can start utilizing hardware accelerators in just 2 steps:
- Download InAccel’s AMIs from aws
- Start his Spark application and just add “-inaccel” before submitting the spark job.
The Inaccel FPGA manager is delivered as a dockerized service, enabling its seamless integration to any FPGA accelerated cloud provider and/or local infrastructure, as well as fast deployment, update, and on demand scaling. The only requirement is to ensure that docker is running in your host and obtaining acceleration services is simple as running “docker run inaccel/fpga-manager”.
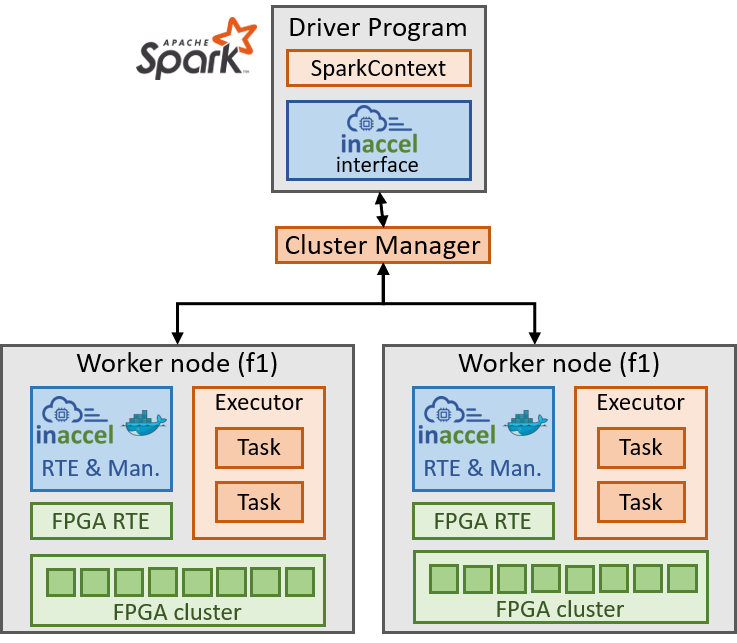
InAccel cluster mode for Spark ML acceleration
Inaccel’s FPGA manager docker container comprises both an FPGA manager to schedule, orchestrate, and monitor the execution of the accelerated applications but also the required FPGA runtime system. The dockerized runtime system detects the FPGA platform (aws F1) and manages the interaction/communication with the FPGA (i.e., loading the accelerator, transferring input data and results), making it transparent to the application.
Hence, Inaccel offers an FPGA abstraction layer and no modifications are required in the application’s code or the infrastructure.
Performance evaluation
The Accelerated ML suite can offer 3x faster execution time and 3x lower TCO. In a comparison that we did with r5.12x that costs overall the same, InAccel’s ML suite finished 3x times faster. That means you get your results 3x faster and you pay 3x less in aws. In the following figure you can see the total execution time to run Logistic Regression under Spark. In the case of r5.12x with 48 cores the total time was around 3700 seconds while using InAccel’s ML suite it dropped to 1700 seconds. The time it takes to load the data and the data extraction takes longer as it is done on 8 cores that are supported by the f1.2x instances but the most computation intensive task takes much less time to run on the FPGAs using InAccel ML suite.
You can try now to speedup your Spark ML applications without any prior knowledge on FPGAs and see how faster you can tun your applications at www.inaccel.com .
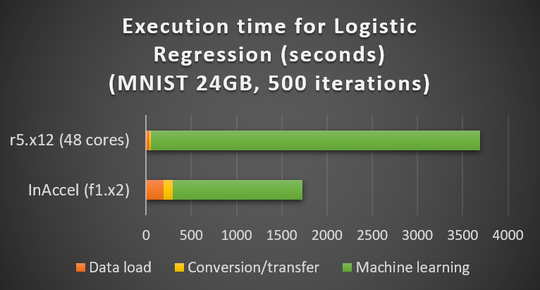
Speedup of Logistic Regression using inaccel ML suite
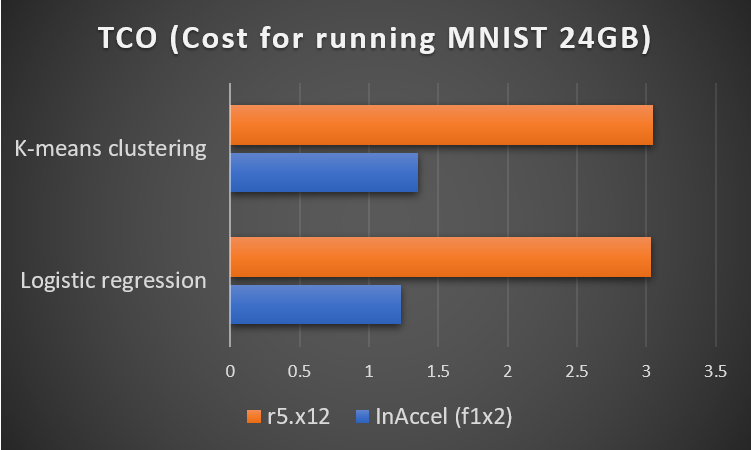
TCO comparison using inaccel accelerators